We present the basics of our flexible word-based self-indexes (FWSI). As in the case of our non-flexible WSI, FWSI are new indexing structures that both permit to implicitly represent the indexed text and, at the same time provide fast sublinear-time searches.
Apart from the WSI that indexed the exact-words from the original text, the flexible WSI permit to deal with a normalized version of the original text, so that only the meaningful words are indexed, and still allows recovering the original text. Normalization is a used-defined function that can consider: stemming, case folding, stop-word removing,... and that maps any source word to its normalized version (Maps, MAP --> map), or to the null-word (stopword --> null-word).
The idea behing our FWSI is simple: we split the text into a sequence of words and separators (no spaceless-model is used), where words are those tokens that normalization does not map to the null word. Separators are now: a sequence of non-alphanumerical chars. Yet any non-meaninful word is also considered as a (part of a) separator. Then,
- all the words are assigned an integer ID to create a sequence of IDs (SID) that represents the part of the source text composed of the valid-words, and that is finally represented with an int-based self-index (ISI), as in a WSI.
- the separators are kept in the presentation layer (this is required as the ISI layer does not indexes separators) in a compact way.
As in the WSI, by keeping the assignment word <--> id , searches implying words and phrases of words can be delegated into the ISI layer. The searched pattern is firstly normalized to obtain the sequence of IDs of the valid-words it contains, and that sequence of IDs makes up the pattern searched for within the ISI layer.
General structure
The general structure of a flexible WSI is shown in the next figure (actually that for a FWCSA). The FWSI differs mainly from the non-flexible counterparts in the presentation layer. Since both words and separators alternate in the text, assuming that the text is "word1, sep1, word2, sep2, word3, sep3 ...":
- the ISI layer will represent IDS of the normalized words "word1, word2, word3"... This is done as in the regular WSIs.
- the presentation layer needs to maintain information to:
- know the variant of each normalized word (we want to recover the original text, and the ISI-layer keeps the ID of the normalized word, but several variants could be mapped to such normalized word during normalization.
- represent the sequence of separators: "sep1, sep2, sep3,..."
- map words to its original char-based position in the source text so that char-based searches (locate / extract / display) are also allowed.
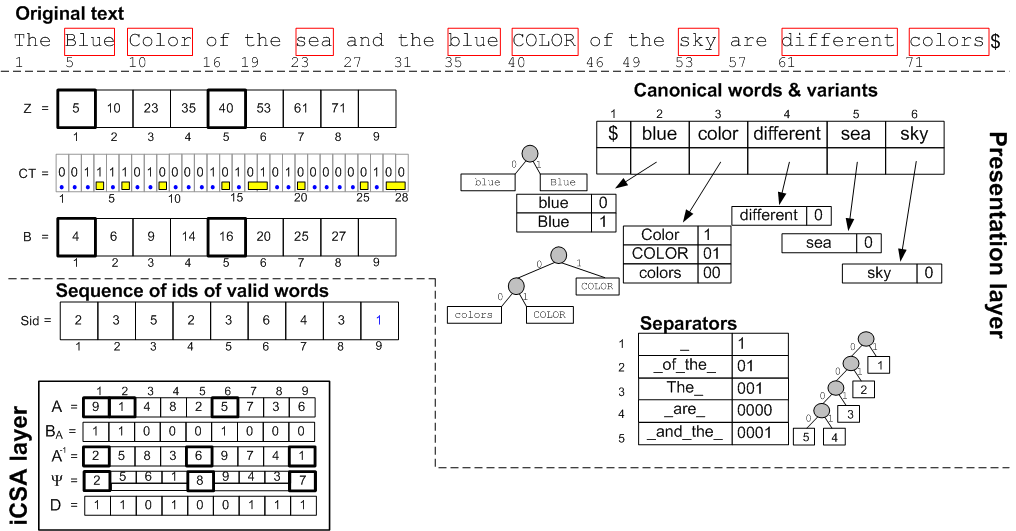
Bit-oriented Huffman coding is profuselly used in the presentation layer: Separators are given a word-based Huffman code, and also, each normalized version of a valid-word is given a word-based huffman code that permit to identify each one of them (a different Huffman coding is used for the variants of the same normalized word). Basically, a bit-stream CT contains: (i) the huffman code "001" of the 1st separator "The "; (ii) the huffman code "1" that represents the 2nd variant of the normalized word in SID[1] (that is, "Blue"); (iii) the huffman code "1" of the 2nd separator (a blank space); (iv) the huffman code "1" that represents the 2nd variant of the normalized word in SID[2] (that is, "Color"); (v) and so on ...
In addition, an array B permits us to synchronize the initial position (within CT) of the codeword associated to the variant of the i-th valid word. For example B[5]= 16, indicates that the codeword of the variant associated to the 5-th valid word starts in CT[16]. Actually, since CT[16..17] = "01", and the 5th valid word has the ID= SID[5]= 3 ("color"), we quickly recover the variant "01" = "COLOR" which is the 5th valid word from the source text. From there on, extracting the source text requires only decompressing the next separator from position CT[18,19], then the variant of the word SID[6],... and so on.
Finally, array Z keeps the char-offset in the original text, for the i-th valid word.
Note that to save space, only some regular samples of Z and B are actually kept, yet the remaining values can be recovered by performing decompression from a sampled position in CT. Note that the sampling in Z only affects char-based Locate and Display search times.
A more detailed discussion is included here:
Antonio Fariña, Nieves Brisaboa, Gonzalo Navarro, Francisco Claude, Ángeles Places, and Eduardo Rodríguez. Word-based Self-Indexes for Natural Language Text. ACM Transactions on Information Systems (TOIS), To appear, 2012. [abstract] [bibtex] [pdf]
Performing searches
Apart from the word-based search operations in WSI (performed on a normalized version of the searched pattern), the FWSI permits also the following char-based search operations:
- locateFWSI(P ) gives the list of the positions of the text (T), measured in byte offsets, where the canonical words of P match.
- displayFWSI(P, radix): For each occurrence of a variant of P in the source text, it retuns a snippet of 2*radix+len(P) chars centered in those occurrences of the pattern P.
- extractFWSI(s, e) returns the substring T [s, e].
Implementation details of a FWSI (pizza-chili wise)
As in the non-flexible WSI we separated the build and search programs from the actual implementation of the indexes. The interface that our Flexible word-based Self-index (WSI) must implement is the following one:FWSI. Interface.h
The FWSI permits the following operations included in file interface.h:
- int build_index (uchar *text, ulong length, char *build_options, void **index);
- int save_index (void *index, char *filename);
- int load_index (char *filename, void **index);
- int free_index (void *index);
- int index_size(void *index, ulong *size);
- int get_length(void *index, ulong *length);
- int count (void *index, uchar *pattern, ulong length, ulong *numocc);
- int locateWord(void *index, uchar *pattern, ulong length, ulong **occ, ulong *numocc, uint kbefore);
- int displayWords (void *index, uchar *pattern, ulong length, ulong numc, ulong *numocc, uchar **snippet_text, ulong **snippet_lengths, uint kbefore);
- int displayTextOcurrencesNoShow(void *index, uchar *pattern, ulong length, uint wordsbefore, uint maxnumc);
- int extractWords (void *index, ulong fromWord, ulong toWord, uchar **text, ulong *text_length);
- int locate (void *index, uchar *pattern, ulong length, ulong **occ, ulong *numocc);
- int extract (void *index, ulong from, ulong to, uchar **snippet, ulong *snippet_length);
- int display (void *index, uchar *pattern, ulong length, ulong numc, ulong *numocc, uchar **snippet_text, ulong **snippet_lengths);
This interface is implemented by our prototype FWCSA to obtain the library fwcsa.a that will be linked with files build_index.c and run_queries.c to obtain respectively the programs to (i)build a FWSI from a given text, and once that self_index is constructed and saved to disk, (ii) to perform searches f or a given set of patterns against such FWSI.
Flexible WCSA. (Source code)
The source code for our FWCSA is available here: fwcsa.tar.gz. The normalization function included in that package considers case-folding and removes stop-words. It does not use stemming. In our ACM-TOIS paper we also tried a different version using Porter' stemming, the source code for that version of FWCSA is available here: fwcsa.Porter.tar.gz
In both cases, after unpackaging those files, follow the instructions in the files:
- readme.fst.txt and
- README.2nd.txt (within the sourceCode directory)
You will be led in the process of compiling the source code to obtain (among others), the programs:
- BUILDwcsa and SEARCHwcsa
You will also find some scripts (folder "scripts") to build the FWCSA over a 100MB text from pizza-chile site (english.100MB) and perform searches for some sets of patterns from that text collection. Note that, folder "texts" contains a script to download english.100MB corpus directly from the pizza-chili site.
Building the FWCSA (BUILDwcsa program)
During construction a source text file is processed, and the result is a set of files named outbasename* that contain the "in-disk" compressed representation of the FWCSA self-index built over the source data.BUILDwcsa
Syntax: ./BUILDwcsa infile outbasename ["BUILD_OPTIONS"]
+ where:
- infile: is a text file.
- outbasename: is the base name for all the files used by the index (19 for FWCSA).
- BUILD_OPTIONS: Specify building parameters (required for the iCSA layer: sampling and compression of psi; and those for the presentation layer). All those options appear between ""... and will be separated by commas if more than one appear.
Parameters for the presentation-layer
*sB: Distance between samples of the array B
*sZ: Distance of samples of the array Z
*stopfile: Path to a file containing stopwords (to use in the normalization process)
Parameters for the ICSA-layer
*sA: Distance between samples of the suffix array (A)
*sAinv: Distance of samples of the inverse of A
*sPsi: Distance between samples of the psi array
*nsHuff: set to 16 by default (nsHuffx1024 = numOfSymbols). Related to psi compression.
*psiSF : factor for the searches in the samples of psi (set to 1,2,4,8).
+ example of use:
./BUILDwcsa ./texts/english.100M ./indexes/EN100MB "sB=32; sZ=512; stopfile= ../src/english_stopwords.txt; sA=32; sAinv=32; sPsi=32; nsHuff=16; psiSF=4"
Searches in the FWCSA(SEARCHwcsa program)
It loads a set of files named outbasename* that contain the "in-disk" compressed representation of the FWCSA self-index for a given text, and then perform searches over the in-memory self-index. The syntax and some examples follow:Syntax: ./SEARCHwcsa index type [wordsbefore][V] < patterns_file
+ where:
- type: denotes the type of queries:
- C repetitions, counting occurrences. The process is repeated $repetitions$ times and average times are reported (to avoid times equal to "0.000").
- L locating queries. If returns the source text positions (char-based offset) were a pattern occurs.
- D radix-num-char for displaying queries; radix-num-char denotes the number of characters to display before and after each pattern occurrence.
- E extracting queries (char-oriented extract).
- l wordsbefore repetitions, locating queries (word-oriented); $wordsbefore$ sets returned location -wordsbefore- word positions before each pattern occurrence. The process is repeated $repetitions$-times and avg-times are reported.
- d radix-bytes wordsbefore, displaying queries (word-oriented); will extract 2*radix-bytes + lenght(pattern) bytes starting extraction -wordsbefore- words before an occurrence. The extracted snippets are allocated dynamically.
- s maxnumc wordsbefore repetitions, displaying queries. Word-oriented display extracts up to 2*wordsbefore words, starting -wordsbefore- positions before each occurrence. The max number of chars extracted is maxnumc; The extraction is *simulated* $repetitions$-times and avg-times are reported. Note that no-text is returned. ONLY extraction of data is simulated.
- e. extracting queries. (word-oriented extract).
- index: is the base name for the FWCSA used for the searches.
- V. with this option it reports on the standard output the results of the queries.
+ examples of use:
./pizza/SEARCHwcsa ./indexes/EN100MB C 1000 < various/pattsEN100MB/EN100MB.xt1000_1-- This will show some information in the screen and write out a log of statistics to a times*_file.
./pizza/SEARCHwcsa ./indexes/EN100MB l 50 1 < various/pattsEN100MB/EN100MB.xt1000_2
./pizza/SEARCHwcsa ./indexes/EN100MB d 50 5 V < various/pattsEN100MB/EN100MB.xt1000_4
./pizza/SEARCHwcsa ./indexes/EN100MB s 10000 10 < various/pattsEN100MB/EN100MB.xt1000_2
./pizza/SEARCHwcsa ./indexes/EN100MB e < various/pattsEN100MB/EN100MB.intervals.1000words.txt
./pizza/SEARCHwcsa ../indexes/EN100MB L < ../various/pattsEN100MB/EN100MB.xt1000_4
./pizza/SEARCHwcsa ../indexes/EN100MB D 100 < ../various/pattsEN100MB/EN100MB.xt1000_2
./pizza/SEARCHwcsa ../indexes/EN100MB E <../various/pattsEN100MB/EN100MB.intervals.100000chars.txt