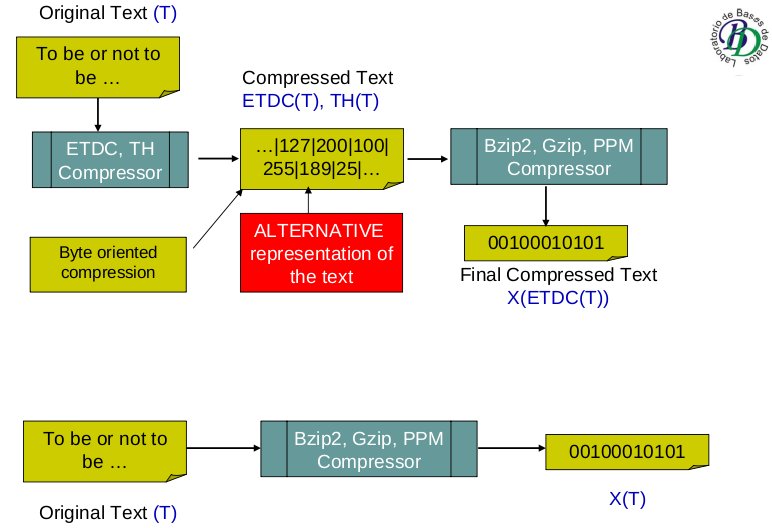
We have used our dense codes ETDC and SCDC as Text compression boosters in 2008. The idea is that we can compress a text Tin a first stage with a word-based byte-oriented compressor (for example ETDC), and the resulting data ETDC(T) is still compressible with a general purpose compressor such as gzip, p7zip, bzip2, or ppmdi. The structure is shown in the next figure:
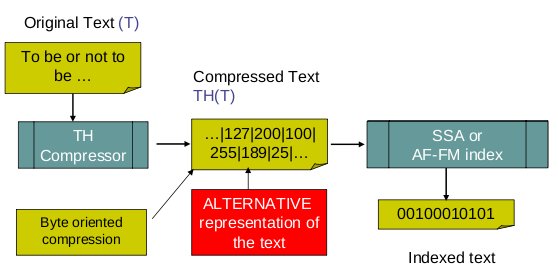
The same idea is also appliable to boost self-indexing when we preprocess the source text with a word-based byte-oriented text compressor using a suffix-free and prefix-free encoding such as Tagged Huffman. The next figure shows this scenario.
We have presented our results in our paper in DCC 2008.
Fariña, A., Navarro, G., Paramá, J. R. Word-based statistical compressors as natural language compression boosters. James A. Storer, Michael W. Marcellin (Ed.). Proc. of the Data Compression Conference (DCC'08), pp. 162-171. Snowbird, USA, 2008. (online) [abstract] [bibtex] [pdf]
With respect to compression, our boosting method using ETDC has permited to obtain not only improvements in compression, but also in compression and decompression speed due to its speed. Speed improves especially when we combine ETDC/SCDC with slower compressors (bzip2, ppm, p7zip), but we also obtained good results with fast compressors such as gzip. Focusing in compression ratio results, we obtained interesting improvements in most cases. We include some partial results in the following figures.
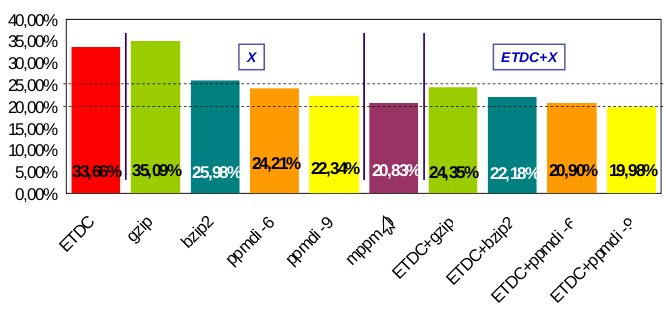
compression ratio (in %) for a 1Gib corpus.
---------------------------
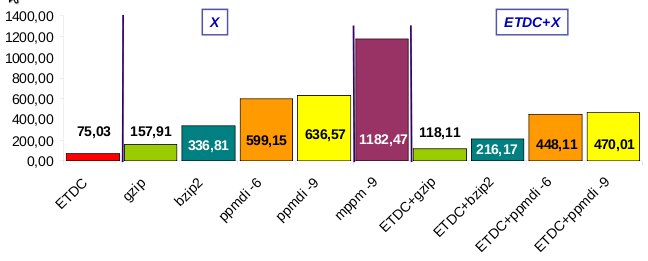
compression time (in seconds) for a 1Gib corpus. Experiments run in Pentium IV @ 3Ghz
We also presented preliminary results shown that self-indexes such as The SSA or the AFFM-index clearly benefit of indexing text compressed with Tagged Hufman instead of self-indexing the original text. Actually, we obtained improvements improvements in space close to 50%, while retaining the same speed at searches. More details will be avaliable at our word-based self-indexing web page.
Journal paper in The Computer Journal.
Fariña, A., Navarro, G., and J. Paramá. Boosting Text Compression with Word-based Statistical Encoding. The Computer Journal 55(1), pp 111-131, 2012. (online). (doi: 10.1093/comjnl/bxr096) [abstract] [bibtex] [pdf]
In 2011, we published an extended version of our paper in DCC'08. Apart from a more exhaustive experimental evaluation, this new paper included:
- SCBDC A new suffix-free technique based on SCDC. It outperforms Tagged Huffman in most aspects while retaining its suffix-free property. This makes SCBDC suitable for self-indexing boosting.
- Boosted online searches Lzgrep is a nice tool that permits to perform searches over text compressed with a lz technique (gzip). The source code is available here. We modified Lzgrep in order it to be able to work over text preprocessed with ETDC and finally compressed with gzip. This software is available at our downloads section.
- Boosting self-indexing with non suffix-free codes (SCDC) We showed that by indexing, not the compressed text obtained by SCDC, but a reversed version of it, we can still boost some self-indexes (such as AFFM, CSA, and SSA). Yet some (very small) variations must be done in the source code of the original self-indexes.


