We present the basics of our word-based self-indexes (WSI). That is, new indexing structures that both permit to implicitly represent the indexed text and, at the same time provide fast sublinear-time searches.
The idea behing our WSI is simple: we split the text into words, we assign each word an integer ID to create a sequence of IDs (SID) that represents the source text, and finally represent that sequence SID with an int-based self-index (ISI), that is built on ints rather than in characters (as typical in the literature).
Then, by keeping the assignment word <--> id , searches implying words and phrases of words can be delegated into the ISI layer.
General structure
Creating a word-based self-index implies two main steps:
- Defining how the text is split into words (parsing), and how words are assigned their integer ID. This permits us to represent the source text as a sequence of integer ids (SID). Yet the reverse mapping id --> word also allows recovering the source text from SID.
- Representing SID sequence with an ISI. That is, a self-index that both gives a more compact representation of SID and provides support for the typical search operations: count, locate, extract, display.
The next figure depicts the general structure our WSIs.
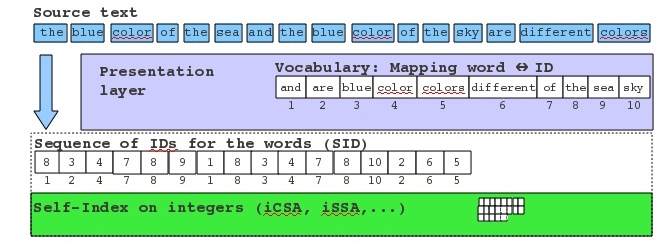
The resulting WSI is a two-layer structure:
- the top layer consists of the vocabulary of words, and maps any word wi to ids corresponding id.
- the bottom layer is composed of an ISI.
We have currently implemented two different ISIs: an int-based Compressed Suffix Array (iCSA) and an int-based Succint Suffix Array (iSSA). This leaded us to the creation of two prototypes of WSIs: The Word Compressed Suffix Array (WCSA) and the Word Succint Suffix Array (WSSI).
Performing searches
The WSI permits the following search operations:
- countWSI(P): counts the number of occurrences of P , which is a token or a sequence in the source text. The occurrences must be exact, that is, the words and the separators of P must match exactly the words from the source text.
- locateWSI(P): gives the list of the positions of P in the source text. These positions are given in terms of word offsets, not character offsets. That is: the 1st word, the 2nd word, ...
- extractWSI(s, e): returns a substring of the source text formed by the s-th to the e-th words (words or separators) from the original text.
- displayWSI(P, radix): For each occurrence of P in the source text, it retuns a snippet of 2*radix words centered in those occurrences of the pattern P.
Implementation details of a WSI (pizza-chili wise)
We tried to build our self-indexes following an extensible/reusable framework following the style of the pizza-chili API (but with a different interface). Therefore, we separated the build and search programs from the actual implementation of the indexes. The interface that any of our word-based Self-index (WSI) must implement is the following one:WSI. Interface.h
The WSI permits the following operations included in file interface.h:
- int build_index (uchar *text, ulong length, char *build_options, void **index);
- int save_index (void *index, char *filename);
- int load_index (char *filename, void **index);
- int free_index (void *index);
- int index_size(void *index, ulong *size);
- int get_length(void *index, ulong *length);
- int count (void *index, uchar *pattern, ulong length, ulong *numocc);
- int locateWord(void *index, uchar *pattern, ulong length, ulong **occ, ulong *numocc, uint kbefore);
- int displayWords (void *index, uchar *pattern, ulong length, ulong numc, ulong *numocc, uchar **snippet_text, ulong **snippet_lengths, uint kbefore);
- int displayTextOcurrencesNoShow(void *index, uchar *pattern, ulong length, uint wordsbefore, uint maxnumc);
- int extractWords (void *index, ulong fromWord, ulong toWord, uchar **text, ulong *text_length);
This interface is implemented by our prototypes WCSA and WSSA to obtain both libraries wcsa.a and wssa.a that will be linked with files build_index.c and run_queries.c to obtain respectively the programs to (i)build a WSI from a given text, and once that self_index is constructed and saved to disk, (ii) to perform searches for a given set of patterns against such WSI.
WCSA and WSSA. (Source code)
The source code is available here: wcsa.tar.gz and wssa.tar.gz
After unpackaging those files, follow the instructions in the files:
- readme.fst.txt and
- README (within the sourceCode directory)
You will be led in the process of compiling the source code to obtain (among others), the programs:
- BUILDwcsa and SEARCHwcsa
- BUILDwssa and SEARCHwssa
You will also find some scripts (folder "scripts") to build the WCSA and WSSA over a 100MB text from pizza-chile site (english.100MB) and perform searches for some sets of patterns from that text collection. Note that, folder "texts" contains a script to download english.100MB corpus directly from the pizza-chili site.
Depending on the self-index (ISI) in the bottom layer of the WSI, we will obtain a WCSA or a WSSA. Also, as the ICSA and ISSA have different parameters, both the WCSA and the WSSA require different parameters at construction time.
Building the WCSA and the WSSA (BUILDwcsa and BUILDwssa programs)
The syntax for both programs is the same (only the parameters vary). In both cases, a source text file is processed, and the result is a set of files named outbasename* that contain the "in-disk" compressed representation of the WCSA and WSSA self-index built over the source data.BUILDwcsa
Syntax: ./BUILDwcsa infile outbasename ["BUILD_OPTIONS"]
+ where:
- infile: is a text file.
- outbasename: is the base name for all the files used by the index (12 for WCSA).
- BUILD_OPTIONS: Specify building parameters (required for the iCSA layer: sampling and compression of psi). All those options appear between ""... and will be separated by commas if more than one appear.
Parameters for the WCSA
*sA: Distance between samples of the suffix array (A)
*sAinv: Distance of samples of the inverse of A
*sPsi: Distance between samples of the psi array
*nsHuff: set to 16 by default (nsHuffx1024 = numOfSymbols). Related to psi compression.
*psiSF : factor for the searches in the samples of psi (set to 1,2,4,8).
+ example of use:
./pizza/BUILDwcsa ./texts/english.100M ./indexes/EN100MB "sA=32; sAinv=32; sPsi=32; nsHuff=16; psiSF=4"
BUILDwssa
Syntax: ./pizza/BUILDwssa infile outbasename ["BUILD_OPTIONS"]
+ where:
- infile: is a text file.
- outbasename: is the base name for all the files used by the index (4 for WSSA).
- BUILD_OPTIONS: Specify building parameters (required for the iSSA layer). All those options appear between ""... and will be separated by commas if more than one appear.
Parameters for the WSSA
*possample: Distance between samples of the suffix array (A) and the source Sequence SID.
*bitsample1: Sampling parameter for the bitmap that marks the sampled suffixes (as sA in the ICSA).
*bitsample2: Sampling for the bitmaps in the Wavelet Tree (WT).
*bitseq1_type: Type of compressed representation for bitmap 1: either rrr02 or brw32.
*bitseq2_type: Type of compressed representation for the WT bitmaps: either rrr02 or brw32.
*seq_type=wt_ptr: Type of representation for the Wavelet Tree: either wt_ptr or wt_noptr.
+ examples of use:
./pizza/BUILDwssa ./texts/english.100MB ./indexes/EN100MB "possample=064;bitsample1=032;bitsample2=032;bitseq1_type=rrr02;bitseq2_type=rrr02;seq_type=wt_ptr"
./pizza/BUILDwssa ./texts/english.100MB ./indexes/EN100MB "possample=064;bitsample1=032;bitsample2=032;bitseq1_type=rrr02;bitseq2_type=rrr02;seq_type=wt_noptr"
./pizza/BUILDwssa ./texts/english.100MB ./indexes/EN100MB "possample=064;bitsample1=032;bitsample2=032;bitseq1_type=brw32;bitseq2_type=brw32;seq_type=wt_ptr"
./pizza/BUILDwssa ./texts/english.100MB ./indexes/EN100MB "possample=064;bitsample1=032;bitsample2=032;bitseq1_type=brw32;bitseq2_type=brw32;seq_type=wt_noptr"
Searches in the WCSA and WSSA (SEARCHwcsa and SEARCHwssa programs)
The syntax for both programs is exactly the same. They load a set of files named outbasename* that contain the "in-disk" compressed representation of the WCSA and WSSA self-index for a given text, and then perform searches over the in-memory self-index. The following syntax and examples are for WCSA, yet those for WSSA are exactly the same (just replace wcsa --> wssa)Syntax: ./SEARCHwcsa index type [wordsbefore][V] < patterns_file
+ where:
- type: denotes the type of queries:
- C repetitions counting occurrences. The process is repeated $repetitions$ times and average times are reported (to avoid times equal to "0.000").
- l wordsbefore repetitions locating queries (word-oriented); $wordsbefore$ sets returned location -wordsbefore- word positions before each pattern occurrence. The process is repeated $repetitions$-times and avg-times are reported.
- d radix-bytes wordsbefore. displaying queries (word-oriented); will extract 2*radix-bytes + lenght(pattern) bytes starting extraction -wordsbefore- words before an occurrence. The extracted snippets are allocated dynamically.
- s maxnumc wordsbefore repetitions displaying queries. Word-oriented display extracts up to 2*wordsbefore words, starting -wordsbefore- positions before each occurrence. The max number of chars extracted is maxnumc; The extraction is *simulated* $repetitions$-times and avg-times are reported. Note that no-text is returned. ONLY extraction of data is simulated.
- e. extracting queries. (word-oriented extract).
- index: is the base name for the WCSA used for the searches.
- V. with this option it reports on the standard output the results of the queries.
+ examples of use:
./pizza/SEARCHwcsa ./indexes/EN100MB C 1000 < various/pattsEN100MB/EN100MB.xt1000_1-- This will show some information in the screen and write out a log of statistics to a times*_file.
./pizza/SEARCHwcsa ./indexes/EN100MB l 50 1 < various/pattsEN100MB/EN100MB.xt1000_2
./pizza/SEARCHwcsa ./indexes/EN100MB d 50 5 V < various/pattsEN100MB/EN100MB.xt1000_4
./pizza/SEARCHwcsa ./indexes/EN100MB s 10000 10 < various/pattsEN100MB/EN100MB.xt1000_2
./pizza/SEARCHwcsa ./indexes/EN100MB e < various/pattsEN100MB/EN100MB.intervals.1000words.txt